엘라스틱 서치를 활용하여 로그 수집과 게시글 키워드 검색 기능을 구축하면서 의아한 부분이 있었다.
역색인 구조인 것은 알겠지만, 어떻게 데이터가 저장이 되고 데이터 다중화는 어떤식으로 진행이 되는지, 가용성은 어떻게 되는지 등이 개념이 잡히지 않았다.
이번 포스팅에서는 Elasticsearch의 데이터 구조가 어떤식으로 잡혀있는지 살펴보려고 한다.
개념 정리
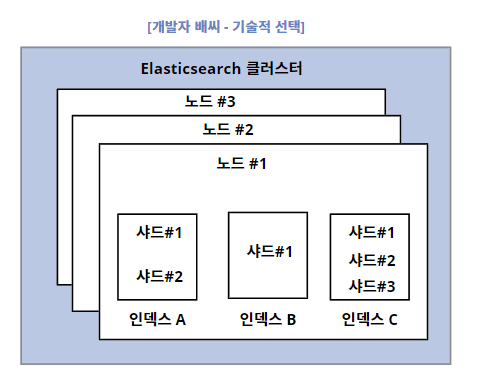
위의 그림을 보면 클러스터, 노드, 샤드, 인덱스로 구성되어 있는 것이 보인다. 하나씩 살펴보자.
1. 클러스터
노드들의 묶음이라고 보면 된다.
클러스터로 묶인 노드들은 노드간 데이터 교환을 위해 http 포트 (9200-9299), tcp 포트 (9300-9399)를 열어둔다. 그러므로 노드 1로 입력된 데이터를 노드 2에서 읽을 수도 있고, 그 반대도 가능하다.
물리적인 구성과 상관없이 여러 노드가 하나의 클러스터로 묶이기 위해선 노드들끼리 클러스터명이 같아야하며, 같은 서버나 네트워크망 내부에 있다하더라도, 클러스터명이 다르면 다른 클러스터로 실행이 되고, 각각 별개의 시스템으로 인식된다.
* 하나의 물리서버에 여러개의 노드 실행도 가능하지만, 하나의 물리서버에 하나의 노드 실행을 권장한다고 한다.
2. node(노드)
클러스터에 묶인 각각의 Elasticsearch를 시작하게 되면, 노드가 생성된다.
이 노드는 동일한 네트워크상에서 클러스터가 존재하는지 확인하고 없으면 노드가 스스로 클러스터를 생성한다. 만약 있으면 같은 이름을 가진 클러스터에 노드를 연결한다.
필자는 클러스터, 노드, 샤드 개념을 접목하여 거대한 서비스를 만드는 것이 아니였고, 1주일 안에 로그 수집 역할을 모두 마쳐야하는 상황이였기때문에 단일 노드로 생성하였다.
하지만, 노드의 개수가 1개라면 프라이머리 샤드만 존재하고 복제본은 생성되지 않는다. 아직 샤드 개념을 모르기때문에 무슨 개념인지 이해가 안갈거지만 밑에서 설명하겠다.
아무튼 작은 클러스터라도 데이터 가용성과 무결성을 위해 최소 3개의 노드로 구성하는 것이 적합하다고 생각한다. 만약 새로운 프로젝트에서 Elastic을 활용하면 구조를 좀 더 학습하고 아키텍처를 설계할 것이다.
3. index (인덱스)
elasticsearch에서는 단일 데이터 단위를 도큐먼트라고 부른다. 그리고 이 도큐먼트를 모아놓은 집합을 인덱스라고 부르며 버전 7이후로 인덱스의 개념을 '테이블'로 보면된다. (필자는 버전 7을 사용하였다.)
그리고 인덱스는 기본적으로 샤드 단위로 분리되고 각 노드에 데이터(도큐먼트)를 분산되어 저장한다.
즉, 인덱싱을 할 때 노드 내부에 논리적으로 데이터 저장공간(샤드)을 만들어 나누면 이제 동시에 여러 데이터를 분산해서 저장할 수 있다.
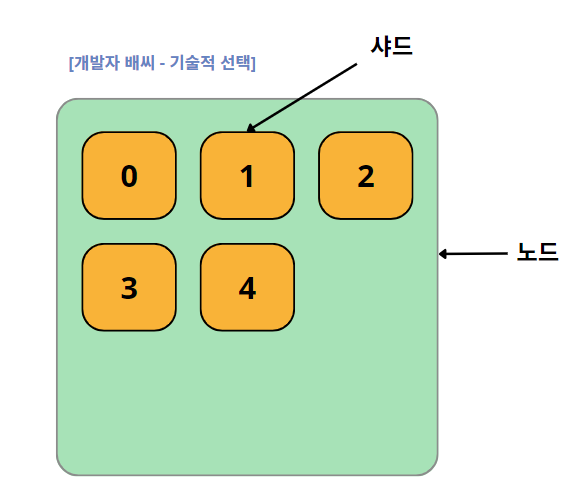
4. shard(샤드)
클러스터에 노드를 추가하면 샤드들이 각 노드로 분산되고, 디폴트로 1개의 복제본을 생성한다. 이때 처음에 생성된 샤드를 프라이머리 샤드(primary shard), 복제본(replica)을 리플리카라고 부른다.
샤드는 일종의 파티션과 같은 의미로, 인덱스의 도큐먼트를 분산해서 저장하는 저장소라고 볼 수 있다. 그래서 샤드의 개수에 따라서 노드에 분산해서 저장소를 만들고, 거기에 도큐먼트들을 저장한다.
elasticsearch 7버전 이상부턴 디폴트가 1로 변경되었고, 이전 버전부터는 디폴트로 5개를 가진다.
샤드의 개수는 데이터의 크기가 크다면 디폴트로 유지하는 것을 권장하고, 응답 속도에 맞게 개수를 늘려야한다. 대신 샤드는 인덱스를 생성할 때만 설정할 수 있다.

그렇다면 샤드가 많을수록 좋은가?
쿼리를 수행하면 샤드의 개수만큼 cpu의 스레드를 사용하게 되는데 샤드의 개수가 많아진다면 리소스를 많이 사용하게 된다. 그래서 작은 데이터일 때 샤드 1개나 샤드 2개의 검색속도가 비슷하다고 하면 샤드 1개만 사용하는게 더 효율적이다.
필자는 별도의 설정을 하지 않았기 때문에 샤드 1개로 구성하여 서비스하였다.
5. replica(복제본)
primary shard(샤드)의 복제본이다.
같은 샤드와 복제본은 동일한 데이터를 담고 있으며 반드시 서로 다른 노드에 저장이 된다. replica(복제본)은 프라이머리 샤드의 개수만큼 생성되며, 인덱스 생성시에만 개수를 설정할 수 있다.
여기서 중요한 점은 primary shard와 replica는 같은 노드에 위치하지 않는다는 점이다. 이것은 가용성과 관련되어있다.
예를 들어, 노드의 개수 4, 샤드의 개수 5, replica의 개수 1이라면 아래와 같이 샤드와 replica가 분산되서 저장된다.

4개의 노드에 5개의 프라이머리 샤드가 존재한다면 복제본 또한 5개가 생성이 된다. 프라이버리 샤드와 복제본은 각각 다른 노드에 생성되고, 복제본도 또 다른 샤드로 간주하기 때문에 전체 샤드의 개수는 10개가 된다.
Q. 만약 노드의 개수가 1개라면?
필자는 단일 노드로 구성하였다고 언급하였다. 이때 문제점은 뭐냐면, 프라이머리 샤드만 존재하고 복제본은 생성되지 않는것이다. 위에서 언급했듯이 데이터 가용성과 무결성을 위해 최소 3개의 노드로 구성할 것이라는 얘기를 했다. 즉, 필자가 진행한 서비스에서 단일 노드가 장애가 발생한다면, 해당 노드에 저장되어 있는 모든 데이터들이 문제가 생긴다는 것이다. 만약 노드를 2개 이상으로 구성했다면 복제본은 각자 다른 노드에 저장되어있기 때문에 장애 발생 노드의 데이터를 복제하고 있으니 크게 문제 될 것이 없다는 문제이다. 그래서 아무리 작은 클러스터라도 데이터 가용성과 무결성을 위해 최소 3개의 노드로 구성할 것이라는 결론을 내린 것이다.
즉, replica의 효과로 가용성 증가로 말할 수 있다.
replica는 primary shard와 같은 노드에 존재할 수 없기 때문에 노드 하나가 죽으면, 다른 노드에 있는 복제본에서 데이터를 가공해서 결국 장애 복구 (fail-over)에 용이하다.
그렇다면 어떻게 데이터 구조가 바뀌는가?
예를 들어, 아래 그림처럼 3번 노드가 죽으면 primary shard 4번이랑 replica 0을 잃게 된다. 하지만 primary shard 4는 노드2에 , replica 0은 노드 2에 존재하기 때문에 데이터를 대체할 수 있다.
즉, elasticsearch 에서 노드가 죽어도 primary shard와 replica 덕분에 데이터를 잃어버리지 안혹 데이터 가용성 및 무결성이 보장된다.

느낀점
프로젝트를 진행하면서 서비스 구현에 급급한 나머지 엘라스틱 서치에 대한 정확한 데이터 구조를 이해하지 않고 결과물만 내는것에 초점이 맞춰졌던 것 같다. 샤드의 복제본을 활용하여 가용성과 무결성을 지키는 것은 서비스 복구의 핵심이라고 생각한다. 만약 다시 한 번 Elasticsearch를 활용한 프로젝트를 진행한다면, 또는 관련된 현업에서 종사하게 된다면 이러한 부분들을 간과하지 않고 설계하는 것에 초점을 맞추고 싶다.
'프로젝트 > 기술적 선택' 카테고리의 다른 글
| [기술적 선택] Webflux의 적용한 이유와 동작 흐름 (0) | 2023.07.22 |
|---|---|
| [기술적 선택] SSE 웹 기술을 활용한 이유 (알림 기능) (1) | 2023.07.22 |
| [기술적 선택] JPA - Optimistic Lock 도입 이유 및 적용 방법 (0) | 2023.06.06 |
| [기술적 선택] Elasticsearch 도입 이유 및 성능 측정 (2) | 2023.06.06 |
| [기술적 선택] 쿼리 성능 개선을 위한 INDEX 적용 (0) | 2023.06.06 |

댓글