개요
최근 코딩 테스트를 치룬적이 있는데 Set 자료구조에 값을 담고 추후 해당 데이터를 List에 담아서 오름차순 정렬을 해야하는 로직이 필요로 하였다. 하지만, 주어진 테스트 케이스는 Set에 들어있는 원소의 값을 List에 담고 반환해주더라도 정답으로 출력되었다. 그래서 오름차순 정렬을 잊은채 제출하고 다른 문제를 풀러 갔다. 만약 예제가 틀렸더라면, 바로 오름차순 정렬을 깜빡한 걸 인지하고 바로 수정하지 않았을까... 엄연히 내 실수긴 하다 ㅎ..
하지만 조금 특이한게 Set에 삽입한 순서를 떠올려보면 정렬을 하지않으면 테스트 케이스도 틀려야했다. 지금까지 필자가 알고 있었던 HashSet은 중복을 허용하지 않고 정렬을 지원하지 않는다고 알고 있었는데 왜 오름차순으로 정렬된 테스트케이스를 맞출수 있었던 것일까...
사실, HashSet은 자동으로 정렬되는 구조인건가?
오늘은 HashSet의 내부구조를 자세히 알아보고 어떻게 정렬이 돼서 출력된 것인지 디버깅을 통해 분석해보려고 한다.
문제점
[예제 1]
import java.util.Set;
public class HashSetSort {
public static void main(String[] args) {
Set<Integer> set = new java.util.HashSet<>();
set.add(3);
set.add(1);
set.add(4);
set.add(2);
for(int x : set) System.out.print(x+" ");
}
}
위와 같이 HashSet 자료구조에 3 -> 1 -> 4-> 2 순으로 데이터를 주입하고 차례대로 출력을 해봤다. 앞서 언급한 것처럼 HashSet은 중복을 허용하지 않고 정렬을 지원하지 않는다는 개념과 달리 오름차순으로 정렬되었다. 일단, 여기서 나의 개념을 깨뜨렸다. 그래! HashSet은 정렬이 되는 구조라고 확신하였다. 하지만, 다음 코드에서 나의 개념이 곧바로 깨졌다.
[예제 2]
import java.util.Set;
public class HashSetSort {
public static void main(String[] args) {
Set<Integer> set = new java.util.HashSet<>();
set.add(3);
set.add(1);
set.add(4);
set.add(2);
set.add(17);
for(int x : set) System.out.print(x+" ");
}
}
이번에는 코드를 조금 수정해서 '17'의 숫자를 삽입해봤다. [예제 1] 에서 나온 원리대로 생각해보면 [예제 2] 또한 오름차순으로 정렬이 되어야한다고 생각했다. 하지만 예상과 달리 17이라는 값은 애매한 위치에서 출력되었다.
내가 모르는 뭔가 숨겨져있다.
버킷 초기 사이즈 분석
먼저 위의 코드에서 set.add(3) 코드를 볼 때 최초의 HashSet에 처음 데이터 값을 넣을 때의 상황을 디버깅을 통해 분석해보기로 하였다. 3을 기준으로 디버깅을 해볼 때 3은 처음 들어가는 값이므로 아무것도 저장된 것이 없으니 resize를 진행하는 것을 알 수 있다.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
** 생략 **
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
** 생략 **
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
threshold = newThr;static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
위의 코드들은 set.add(value) 코드를 상세 디버깅을 통해 나오는 코드이다.
여기서 중요한 것은 DEFAULT_LOAD_FACTOR와 DEFAULT_INITAL_CAPACITY는 불변성을 가지고 있는 값으로 세팅되어있는데 DEFAULT_INITAL_CAPACITY 의 말뜻은 직역해보면 바로 해석된다. 최초 수용량은 16개의 버킷 리스트를 생성한다는 것이다. 즉, set에 첫 데이터를 주입할 때 초기 버킷 사이즈는 16개로 설정되며 그 후에 add() 연산을 통해 주입되는 value값들의 모듈러 연산으로 도출된 해시값으로 연결된다.
* DEFAULT_LOAD_FACTOR에 대해선 밑에서 설명
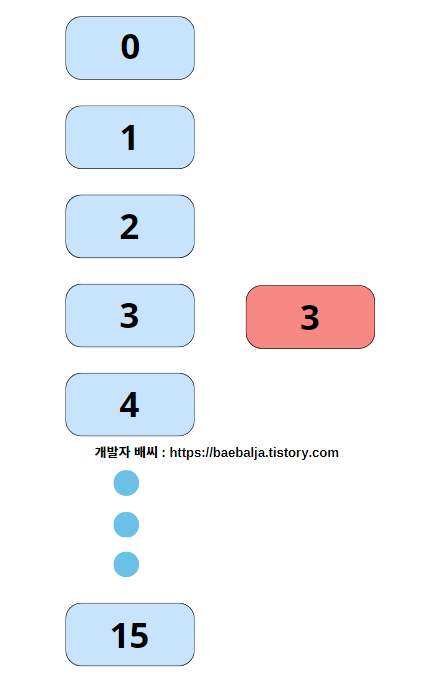
처음에 3이라는 원소를 주입하였을 경우 3%16 -> 3이라는 값이 도출되므로 초기에는 위와 같이 구조화되어있을 것이다.

다음은 1, 4, 2 순으로 집어넣었을 경우, 각각 모듈러 연산을 통해 위와 같이 연결되어있을 것이다. 즉, 모듈러 연산을 통해 중복된 해시값은 나오지 않는다. 그래서 set의 데이터들을 출력해보면 해시순대로 연결된 데이터들을 출력하기 때문에 오름차순으로 출력되는 것이다. (정렬돼서 나온 이유)
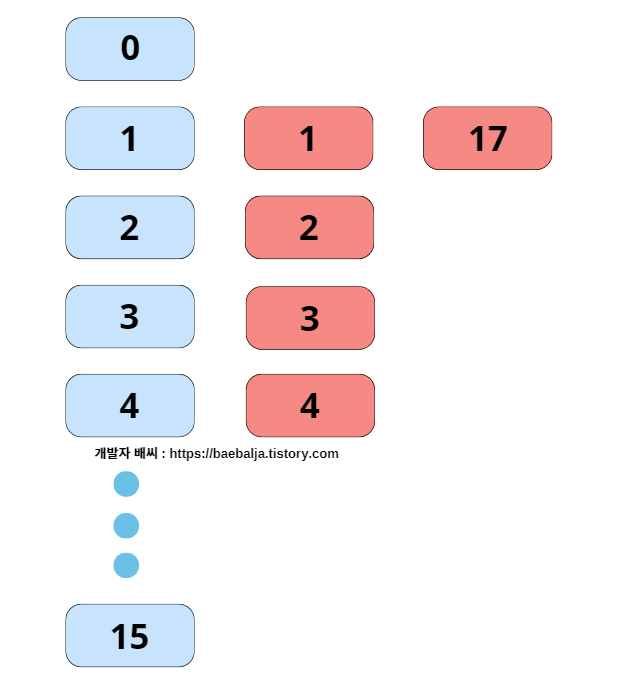
다음은 17의 값을 넣었을 때 17%16 -> 1의 해시값이 도출되므로 중복된 해시값이 나오며 충돌이 발생한다. 그러면 위의
그림처럼 연결될 것이다. 이제서야 의문이 풀린다. {3, 1, 4, 2, 17} 순으로 무작위로 데이터를 주입하였을 때 위의 그림처럼 연결되어있을 것이며 그림대로 순차적으로 나열해보면 아래처럼 출력되는 것이다.
버킷 사이즈의 변화 시점
일단 Set 자료구조에 데이터를 주입하면 초기 수용 사이즈는 16개로 설정된다는 것까지 이해했다.그럼 여기서도 문제가 생길것이라고 판단되는데, 해시 버킷이 16개면 Collision(충돌)이 너무 많이 발생할 것이라고 생각한다. Java 같은 경우 해시 값을 통해 나온 값을 해당 해시 노드에 LinkedList 형태로 연결되며 값을 찾을 때마다 해당 버킷에서 선형 탐색인 O(N)의 시간을 가지게 된다. 그러면 버킷 사이즈가 16인 것은 매우 작은 값이며 언젠가는 늘려줘야하는 시점이 분명히 있을 것이라고 생각했다.
이전에 DEFAULT_LOAD_FACTOR에 대해서 추후 설명하겠다고 적었는데 요놈. 요놈이 newThr를 업데이트 해주는 중요한 역할을 한다. 여기서 newThr는 new Threshold의 줄임말 같은데 Threshold는 한계, 경계, 임계치를 의미한다.
static final float DEFAULT_LOAD_FACTOR = 0.75f;

DEFAULT_LOAD_FACTOR는 위와 같이 불변 변수 0.75f로 설정되어있다. 그러니까 위의 코드를 보면 최초 생성된 newCap은 16이며, newThr은 그 값의 75%인 12를 담고 있는 것이다. 이후 threshold = newThr 로 값을 저장하게 된다. 즉, threshold를 기준점으로 삼아 해당 값의 임계치를 넘어가게 되는 순간 버킷 사이즈를 늘려주는 것이다.
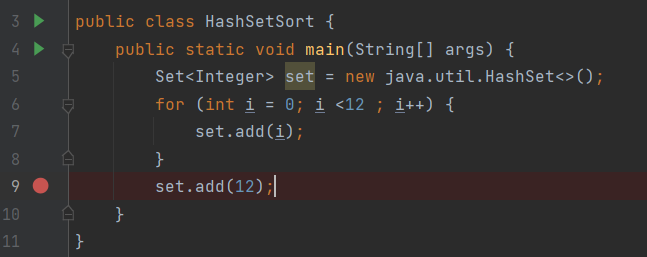
실행을 통해 한번 알아보자. 위의 코드에서 디버깅 지점을 설정해주고, 해당 지점 이전에 12개의 원소를 채워줬다. 그리고 13번째 원소를 주입할 때 threshold의 값을 넘어설테니 뭔가 변화가 있을 것이라고 판단했다.

여기서 걸린다. 원소 12개 이하를 주입하였을 때 해당 if문은 걸리지 않았지만 threshold의 값 12를 넘어갈 경우 걸리게 된다. 이후 resize를 호출하게 된다.

여기서 newCap에 oldCap(16)의 left shift 연산을 통해서 2배의 값을 가지게 된다. 동일하게 threshold에도 같은 방식으로 2배 늘려주는 것을 볼 수 있다.
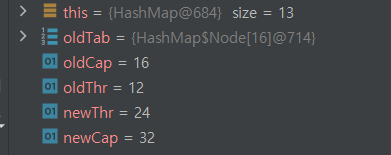
요약하자면, HashSet의 크기는 요소의 수에 따라 동적으로 조절된다. 로드 팩터는 HashSet이 언제 크기를 조절할지를 결정하는 요소이다. 로드 팩터의 기본값은 0.75이며 이것은 HashSet이 버킷의 75%가 채워진 경우 크기를 조절하도록 지시하는 용도이다.
즉, 요소를 추가할 때 HashSet의 크기가 로드 팩터를 초과하게 되면, 내부적으로 크기를 두 배로 확장하고 모든 요소를 새로운 크기의 버킷 배열에 다시 해싱한다. 이렇게 함으로써 해시 테이블의 성능을 유지하고 충돌을 줄이게 되는 것이다.
추가적으로 set.remove(12)를 했을 경우, 요소를 제거할 때 크기를 줄이는 코드는 발견하진 못했다. 그래서 크기 조절 작업은 일반적으로 HashSet에 요소를 추가할 때 발생하며, 요소를 제거할 때는 크기를 줄이지 않는다고 결론지었다.
즉, 버킷 사이즈 숫자를 넘는 값이 들어올 경우 모듈러 연산을 통해 해싱되니 정렬은 무슨... 뒤죽박죽으로 나온다.
마치며
HashSet이 자동 정렬되는 자료구조로 되어있으면 코딩 테스트 문제 1문제를 맞출수 있었을텐데,,
아쉽지만, HashSet은 정렬을 지원하지 않는다.
코딩테스트 테케만 맞았고, 히든 테케에 따라 오답 처리 되었을 것 ㅎ;;
'개발 일지 > Java' 카테고리의 다른 글
| [Java] Integer.valueOf(127)==Integer.valueOf(127)은 True? (1) | 2023.08.08 |
|---|---|
| [Java] 해시 충돌 (0) | 2022.12.19 |
| [Java] equals 와 hashCode (0) | 2022.12.18 |
| [Java] public static void main 인 이유? (0) | 2022.12.18 |
| [Java] Java 8 / Java 11 버전 별 특징 (0) | 2022.12.17 |

댓글