개요
카프카는 브로커의 장애에도 불구하고 연속적으로 안정적인 서비스를 제공하면서 데이터의 유실을 방지하며 유연성을 제공한다. 이전에 게시한 포스팅을 보면 과거 프로젝트를 진행하면서 아쉬웠던 부분들을 회고하며 가용성을 유지하는 환경으로 재구성하였다. 이때 REPLICATION FARTOR라는 옵션을 설정을 하면서 복제 파티션을 만들도록 했던 것을 알고 있을 것이다. 이번 포스팅은 그 원리에 대해서 파헤쳐보는 시간이다. 즉, 어떻게 리플리케이션 동작되는지 알아보고 지금의 답답함을 해소해보려고 한다.
리더와 팔로워
카프카는 내부적으로 모두 동일한 리플리케이션들을 리더와 팔로워로 구분하고, 각자의 역할을 분담시킨다. 여기서 알아야하는 것은 리플리케이션들 중 리더를 하나 정하고 모든 읽기와 쓰기는 그 리더를 통해서만 가능하다. 그리고 메세지를 발행하는 프로듀서는 그 리더에게만 메세지를 보내게 된다. 또한 컨슈머도 오직 리더로부터 메시지를 가져온다.

위의 그림에서 bae 토픽의 파티션 수는 하나고 리플리케이션 팩터 수는 3이다.
흐름을 이해해보면, bae 토픽으로 메세지를 전송하면 읽고 쓰기가 가능한 리더 파티션으로 메시지를 보낸다. 또한, 컨슈머도 리더 파티션으로 메시지를 가져올 것이다. 이때 팔로워 파티션들은 가만히 대기만 하고 있는 것이 아니다. 만약, 리더 파티션에 장애가 발생했다면, 그에 대한 사주 경계를 지속적으로 하고 있어야 한다. 즉, 지속적으로 리더 파티션이 새로운 메시지를 받았는지 확인하고, 새로운 메시지가 있다면 복제하는 흐름이다.
리더와 팔로워는 ISR(InSyncReplica)라는 논리적 그룹으로 묶여 있는데 그 이유는 해당 그룹에 속한 팔로워들만이 새로운 리더의 자격을 가질 수 있기 때문이다.
쉽게 설명하자면, 개발자 배씨가 대규모 전투를 지휘하고 있는 수장이라고 가정해보자. 그리고 나를 믿고 따르는 장군들이 있는데 나와 모든 능력이 같다. 만약 내가 전투를 하다가 전사하게 되면 이들 중 한 명이 대신 수장으로 승격시켜서 바로 병사들을 지휘하도록 해야한다.
즉, 리더는 팔로워들이 뒤처지지 않고 리플리케이션 동작을 잘하고 있는지 감시하고 만약 이들 중 오류, 장애 등 여러가지 이유로 복제해가지 못하는 팔로워들은 리더 자격에서 박탈당하게 된다. 또한, ISR 내에서 모든 팔로워에서 복제가 완료되면, 리더는 내부적으로 커밋을 하게 되는데, 이때 커밋된 메시지만 컨슈머가 읽어갈 수 있다.
why?
이 부분은 새롭게 알게된 내용이기도 하다. 프로듀서가 메시지를 리더에게 전송하면 즉시 컨슈머가 컨슘해가는 줄 알았는데 내부적으로 복제를 모두 완료한 후, 커밋을 한다. 그 이유에 대해서 알아보자.
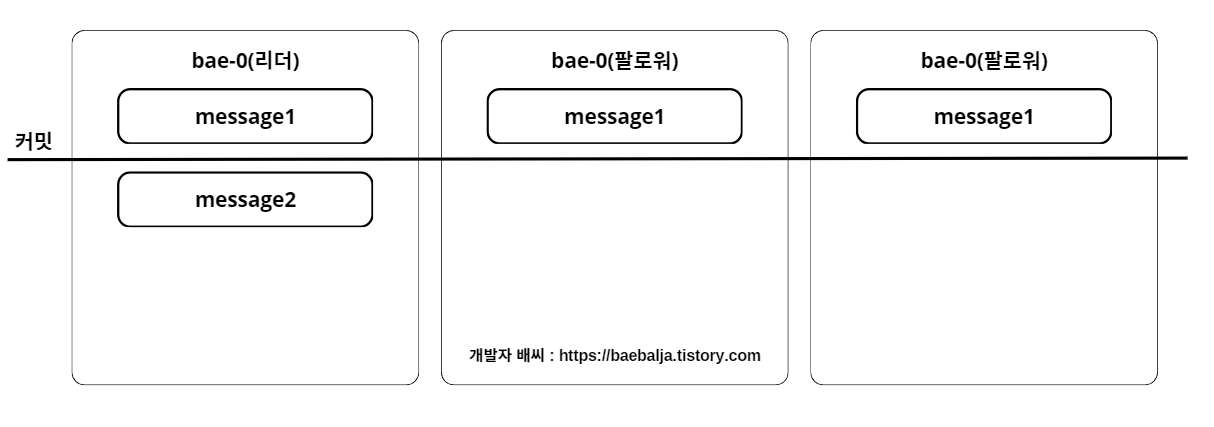
이전과 마찬가지로 토픽은 bae이고 3개의 리플리케이션으로 구성되어있다. 만약, 여기서 commit을 하지 않은 상태의 메시지를 컨슈머에서 읽어갈 수 있다고 가정해보자. 아까 언급한 것처럼 commit이 완료되어야 컨슈머에서 읽어갈 수 있지만 이번 예시는 그렇게 하지않았을 때 발생하는 문제점을 언급하려고 하는 것이다.
다시 말하지만, commit을 하지 않은 상태의 메시지를 읽게 된다면 발생하는 문제점을 그린 것이다.

컨슈머 A는 bae 토픽을 컨슘하고 있고, 커밋되기 전에 읽는 작업을 처리할 수 있다고 가정했으니, 컨슈머 A는 토픽의 파티션 리더로부터 message1, 2를 읽어갔으며, 현재 두개의 팔로워는 message2를 리플리케이션 동작하기 전 상태이다.
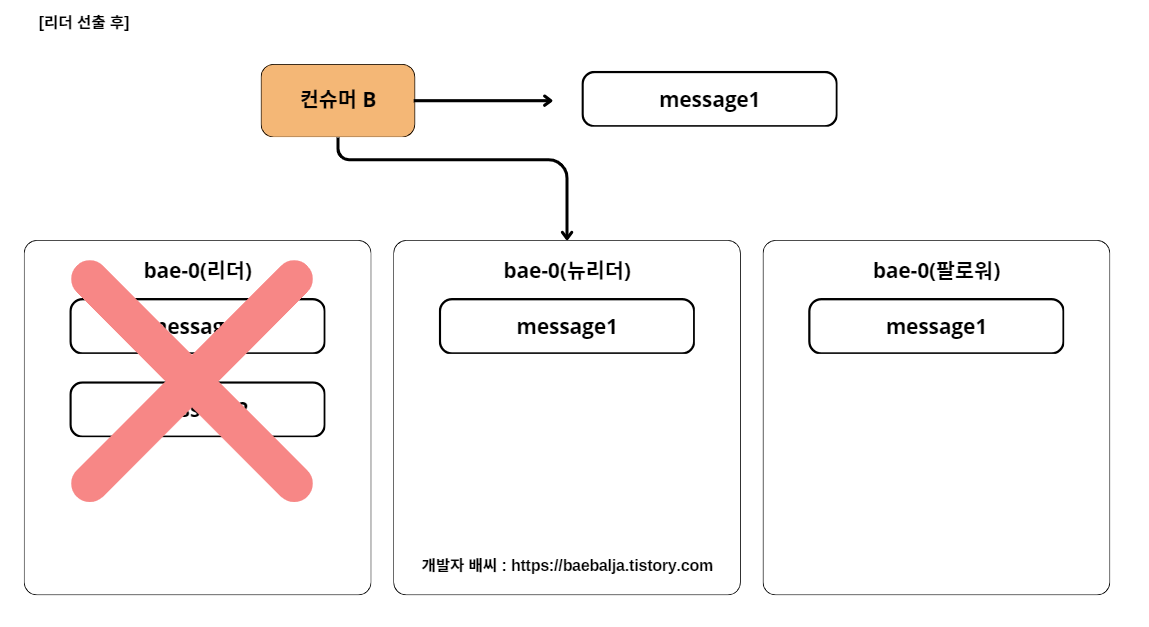
컨슈머 A가 message2를 읽자마자 리더에 장애가 발생했다. 그러면 ISR 그룹 내에 새로운 리더를 할당할 것이다. 위의 그림처럼 뉴리더가 생성이 되고 컨슈머 B가 새로운 리더의 메세지를 읽어오게된다. 그렇다면 컨슈머 A와 컨슈머 B는 동일한 토픽에 컨슘했음에도 메시지가 일치하지 않게 되는 문제점이 발생한다.
아, 이러한 문제점이 발생하니까 commit이 완료돼야 컨슈머가 읽어갈 수 있구나
이해됐죠?
리더와 팔로워의 단계별 리플리케이션 동작

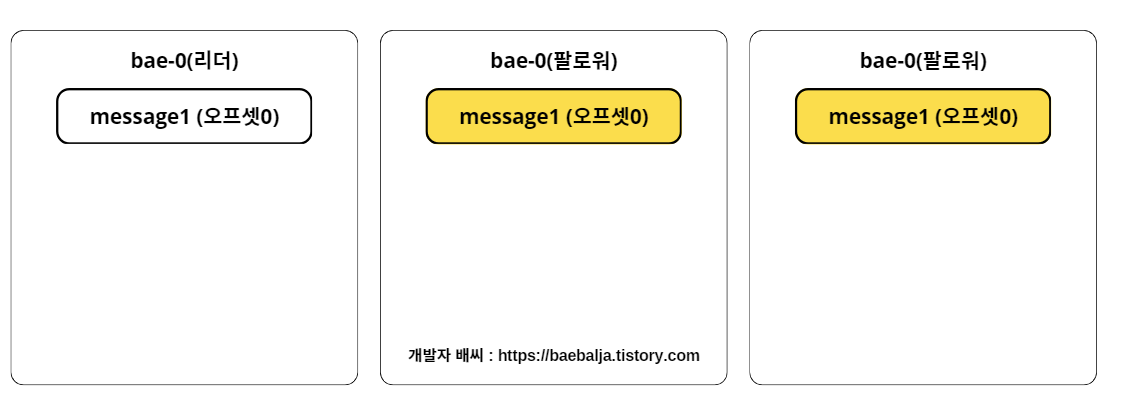
자, 이제는 각 파티션에서 어떻게 메시지들을 리플리케이션하는지 궁금할 때가 되었다. 위의 그림은 bae 토픽에 1개의 파티션과 3개의 리플리케이션 팩터를 갖고 있다. 현재 리더 파티션에서 message1에 대한 메시지를 갖고 있는 상태이며 다른 팔로워들은 메시지를 리플리케이션 하기 전 상태라고 가정하자.

팔로워들은 이제 리플리케이션을 동작하기 위해서 위의 그림처럼 리더 파티션에게 0번 오프셋 메시지 가져오기 즉, fech 요청을 보낸 후 새로운 메시지가 있다는 사실을 인지하고 리플리케이션 된다.
위의 그림처럼 정상적으로 리플리케이션 되었다면 문제가 없지만, 카프카는 또 다른 특징이 존재한다. 카프카와 많이 비교되는 전통적인 메시지 큐인 Rabbit MQ는 트랜잭션 모드에서 모든 미러 (카프카에서 팔로워에 해당)가 메시지를 받았는지에 대한 ACK를 리더에게 리턴하면서 판단하게 된다. 하지만 카프카는 이러한 기능이 없다. 즉, 리더는 각 팔로워들이 리플리케이션 동작을 성공했는지 여부를 알지 못한다는 사실이다.
즉, 위의 그림은 각 팔로워들이 리플리케이션 되었다는 가정하에 그려놓은 그림이며, 만약 실패했을 때 카프카는 어떻게 실패를 감지하고 리플리케이션을 다시 시도하는지가 궁금할 것이다.
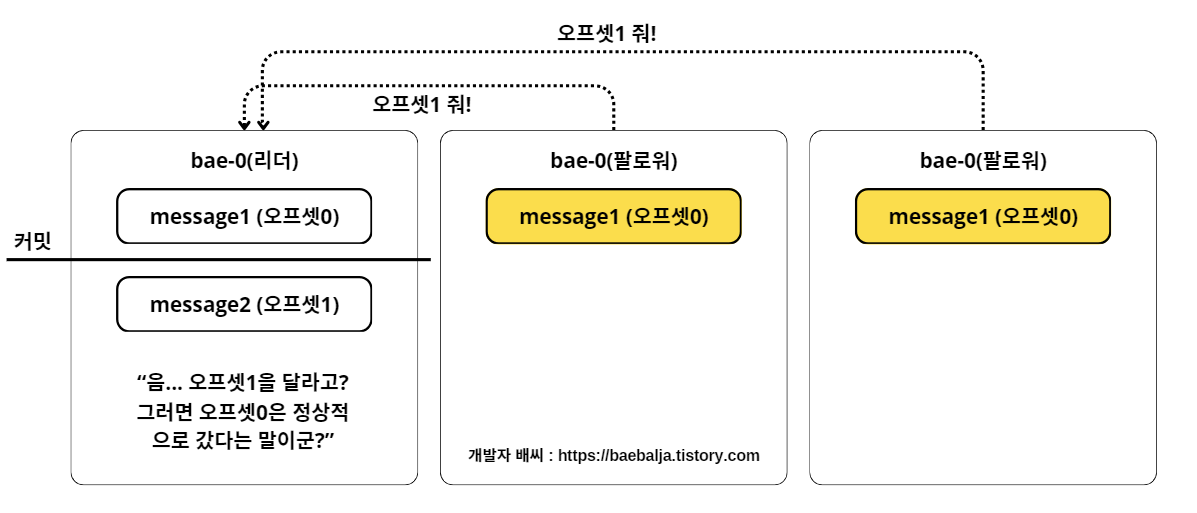
먼저, 위의 그림처럼 메시지 1은 모두 복제되어있다고 가정하고 메시지 2를 프로듀서를 통해 리더가 받았다고 해보자.
그러면 각 팔로워들은 오프셋 1번에 대한 리플리케이션을 리더에게 요청하게 된다. 그러면 리더는 어떻게 생각을 하냐면, 오프셋 0번에 대한 리플리케이션은 완료가 됐다고 인지한다. 이때는 오프셋 0에 대해 커밋 표시를 한 후 하이워터마크를 증가시킨다.
* 하이워터마크 : 마지막 커밋 오프셋 위치
만약, 특정 팔로워가 오프셋 0번에 대한 리플리케이션을 성공하지 못했다면, 오프셋 0번에 대한 리플리케이션 요청을 보내게 되는 것이다. 즉, 팔로워들이 보내는 리플리케이션 요청의 오프셋을 보고, 팔로워들이 어느 위치의 오프셋까지 리플리케이션을 성공했는지 인지할 수 있다.
이후, 팔로워들로부터 1번 오프셋 메시지에 대한 리플리케이션 요청을 받은 리더는 응답에 0번 오프셋 message1 메시지가 커밋되었다는 내용도 함께 전달하게 된다.

이후, 리더의 응답을 받은 모든 팔로워는 0번 오프셋 메시지가 커밋되었다는 사실을 인지하게 되고, 리더와 동일하게 커밋을 표시하게 된다. 이러한 방식을 계속 반복하여 동일한 파티션 내에서 리더와 팔로워 간 메시지의 최신 상태를 유지하는 것이다. 결국, 카프카는 리더와 팔로워 사이에 Rabbit MQ처럼 ACK 통신을 제거함으로써 리플리케이션 동작의 성능을 더욱 높인 것이다.
마치며
몰랐던 내부 동작을 알게되니 아 이래서..? 아 이랫구나.. 이 말만 계속 중얼거렸다. 기술을 사용하는 것도 좋지만, 동작 원리에 대해서 그림을 그리면서 정리하다보니 조금 더 깊숙하게 알게되는 느낌이다. 다음 포스팅에서는 리더에포크와 복구에 대해서 포스팅하고자 한다.
* 참고서적 : 실전 카프카 개발부터 운영까지 - 고승범
'개발 일지 > Kafka' 카테고리의 다른 글
| [Kafka] 컨슈머의 리밸런싱 (2) | 2023.10.25 |
|---|---|
| [Kafka] 프로듀서가 정확히 한 번만 전송하는 방식 (0) | 2023.10.24 |
| [Kafka] 프로듀서의 내부 동작 원리 파헤치기 (1) | 2023.10.23 |
| [Kafka] 내부 동작 원리 파헤치기(2) - 리더에포크 (0) | 2023.10.22 |
| [Kafka] 고가용성과 리플리케이션 & 스프링 부트 테스트 (0) | 2023.08.09 |

댓글