[프로세스란 무엇인가 - 질문정리]
Q. stack pointer 레지스터는 어떤 정보를 저장하나요?
stack은 LIFO 구조로 선입후출 방식인건 알고계시죠? 데이터가 들어올때마다 차곡차곡 쌓였다가 가장 늦게 들어온 놈이 순차적으로 빠져나가는 방식이잖아요?
예를 들어, “자료구조” 라는 책을 먼저 책상에 올리고 “운영체제” 라는 책을 한권 올리고 다음 “DB” 책을 올릴려고 하는데 stack pointer라는 놈이 “운영체제” 책의 표지부분을 가리키면서 여기 올리면 되겠네! 하는 거죠.
즉, stack pointer란 현재까지 할당한 메모리의 끝 주소를 기억하고 있다가 다음에 들어오는 데이터에게 여기서부터 메모리 쓰면 돼! 라고 알려주는 역할입니다.
Q. PCB는 메모리에 어떤 형식으로 저장되나요?

PCB가 프로세스의 중요한 정보를 포함하고 있기 때문에, 일반 사용자가 접근하지 못하도록 보호된 메모리 영역(커널 영역) 안에 있어요. PCB는 Linked List 방식으로 관리된다고 해요! 그래서 프로세스가 생성이 되면 자동으로 해당 프로세스의 PCB가 생성되는데 해당 PCB를 커널영역에 있는 PCB LIST를 찾아서 Head에 갖다 붙이는 거죠.즉, 각 PCB 꼬리에는 다음 PCB 주소값을 가리키고 있다고 생각하시면 될 거 같아요.
그래서 프로세스 종료 시 PCB를 삭제 할 때는 해당 PCB를 찾아서 앞에 연결된 놈과 뒤에 연결된 놈을 서로 연결시키고 제거되는거죠. 그래서 삽입 삭제가 용이하다고 합니다.
Q. 메모리 용량이 크면 클수록 그에 비례하여 처리속도도 빨라지나요? (8GB 16GB메모리의 제품이 있을때 무조건적으로 16GB를 사는게 좋은지)
CPU가 사람이고 책상이 메모리고 책은 데이터, 책장은 하드디스크라고 가정할게요~
메모리(책상)가 넓으면, 작업공간이 그만큼 넓기 때문에, 많은 양의 책을 한꺼번에 펼쳐볼 수 있어요.
그리고 CPU(사람)는 바로바로 참고하고 참조해서 일처리를 할 수 있죠.
만약 메모리(책상)가 좁으면, 작업공간에 펼쳐놓을 수 있는 책이 한정적인 상태가 되므로, 사용빈도가 적은 책(데이터)은 책상 위에서 치워야겠죠? 또한 책상 위에 참고할 책(데이터)이 없으면, 책장(하드디스크)에 가서 책(데이터)을 꺼내다가, 책상(메모리) 위로 가져와야 합니다.
쉽게 말해 책상은 비좁은데 필요한 책이 책상에 없으면, 책을 책장에 넣고 필요한 책을 다시 들고와야하잖아요? 그 과정이 시간이 더 걸린다는 거죠.
메모리(책상) 용량이 크다면, 책상(메모리)에 깔아놓을 책이 많으니까 책장(하드디스크)으로 갈 일이 줄어들겠죠. 결론적으로 일처리가 빨라지겠죠.
[스레드란 무엇인가 - 질문정리]
Q. 멀티쓰레드환경에선 코데스힙 중 스택을 빼고 나머지 세가지 자원을 공유하는 것은 이해가 됐습니다. 쓰레드간에 스택공간만 공유하지 않고 따로 할당하는 이유가 궁금합니다!
스레드마다 하나의 기능을 수행한다고 말씀드렸잖아요?
"Zoom" 을 예로 들면 기능 스레드, 알림 기능 스레드, 상대 화면 스레드 등이 있을텐데
CPU가 여러 스레드를 번갈아가면서 문맥교환이 일어나는데 그 속도가 엄청 빨라서 동시에 수행되는것처럼 느끼는거잖아요? 근데 이 스레드는 아까전에 말씀드린것처럼 각 기능은 독립적입니다.
즉, 스레드마다 수행되고 있는 명령어들이 있는데 그 명령어들은 각 스레드마다 다 다르겠죠.
PC(Program Counter)라는 놈은 수행되고 있는 명령어의 주소를 가리키고 있는데
T1이 CPU를 할당받다가 문맥교환이 일어나면 T1의 PC는 다음으로 수행해야하는 명령어의 위치를
기억하고 있어야해요. 이후에 T1이 다시 CPU를 할당받게 되면 T1의 PC가 가리키고 있는 명령어의 위치부터 다시 수행되게끔 해야하죠. 즉, 명령어가 연속적으로 수행되지 못하고 어느 부분까지 수행했는지 기억할 필요가 있다는 뜻이에요.
따라서 PC 레지스터는 스레드마다 존재해야하고 서로 독립된 공간인 Stack이라는 메모리 영역을 할당 받아야하는 거죠.

추가적으로 PCB가 존재하듯이 Thread별로 존재하는 자료구조인 TCB 라는 것도 존재해요.
Thread별로 존재하는 자료구조이며, PC와 Register Set(CPU 정보), 그리고 PCB를 가리키는 포인터를 가져요!
스레드의 정보가 저장되어 있는 TCB는 PCB보다 데이터가 적어요.
같은 프로세스에서의 스레드간의 문맥교환은TCB 정보만 스위칭하면 되지만
다른 프로세스 간의 스위칭을 할 때에는 PCB / TCB 정보를 모두 스위칭해야하기 때문에
프로세스간 문맥교환은 무겁고 스레드간의 문맥교환은 가볍다라고 이해하시면 좋을거 같아요!
Q. 스레드 처리에 있어서 우선순위는 어떻게 결정하나요?
메모리에 적재된 프로그램을 CPU가 실행할 수 있도록, 운영체제로 하여금 프로세스 또는 스레드에 CPU를 할당하는 것을 스케줄링이라고 해요. 스케줄러는 제한된 자원을 여러 프로세스가 효율적으로 사용하도록 다양한 정책(policy)을 가지고 CPU를 할당합니다. 여기서 정책이란 어떤 프로세스 또는 스레드에게 어떤 순서로 또는 어떤 기준으로 CPU를 할당할지를 결정하는 방법인데요. 참고로 프로세스 스케줄링과 스레드 스케줄링은 할당 대상만 다를 뿐 방식은 동일해요.
그렇기 때문에 스케줄링 방식에 대해서는 이후에 "CPU 스케줄링" 이라는 포스팅으로 게시할 예정이니 조금만 기다려주세요 ㅎㅎ
Q. 스레드는 몇개 일때 효율이 가장 좋은가요? 많을수록 좋은가요?
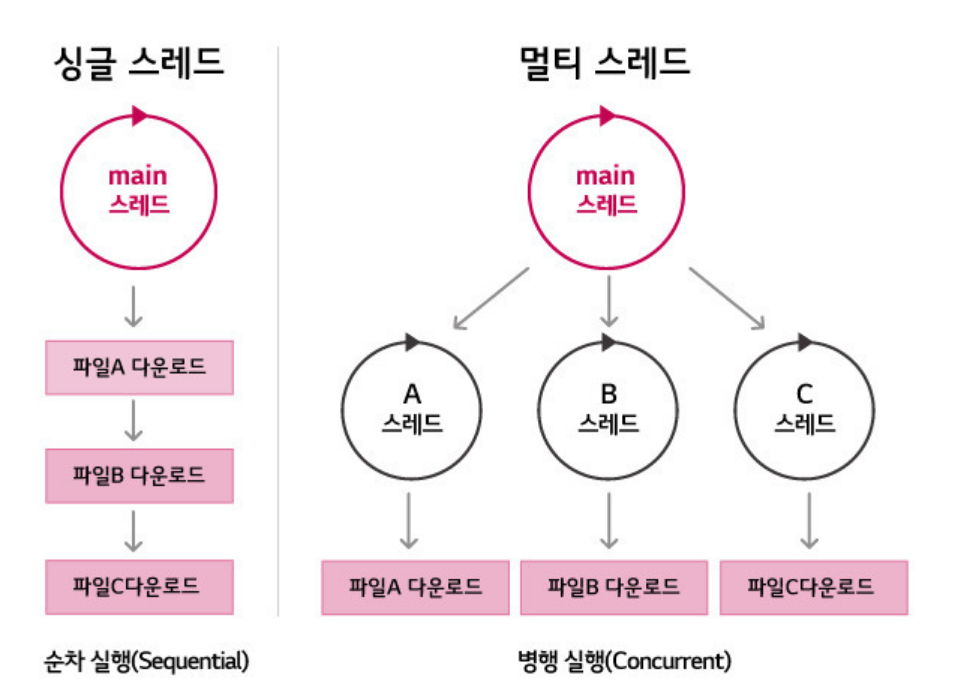
하나의 쓰레드로 세 작업을 처리하는 경우는 한 작업을 마친 후에 다른 작업을 시작하지만, 세 개의 쓰레드로 작업 하는 경우에는 짧은 시간동안 3개의 쓰레드가 번갈아 가면서 작업을 수행하잖아요?
하지만 오히려 세 개의 쓰레드로 작업한 시간이 싱글쓰레드로 작업한 시간보다 더 걸릴 수 도 있는데 그 이유는 쓰레드간의 문맥교환(context switching)에 시간이 걸리기 때문이에요.
그래서 단순히 CPU만을 사용하는 계산작업이라면 오히려 멀티쓰레드보다 싱글쓰레드로 프로그래밍하는 것이 더 효율적이에요. 하지만 CPU 이외의 자원을 사용하는 작업의 경우에는 싱글쓰레드 프로세스보다 멀티 쓰레드 프로세스가 더 효율적이에요. 예를 들면 사용자로부터 데이터를 입력받는 작업, 네트워크로 파일을 주고 받는 작업, 프린터로 파일을 출력하는 작업과 같이 외부기기와의 입출력을 필요로하는 경우가 이에 해당되는 거죠.
또한 CPU가 몇개냐에 따라 또 영향이 끼칠텐데요
만약 스레드가 10개에서 100개로 늘어났다면 CPU가 해야할 처리개수가 더 많아지겠죠
즉, 한사람이 10문제를 풀던것이 100문제까지 늘어나면 더 오랜 시간이 걸리겠죠?
그렇다면 한 사람이 아니라 열명이 문제를 푼다면 처리속도는 다시 빨라지겠죠?
스레드가 많을수록 좋은건 아닙니다. 대신에 스레드가 많아진만큼 처리하는 CPU도 추가된다면 또 달라지겠죠.
즉, 상황에 따라 다를거 같아요!
'남이 읽는 CS' 카테고리의 다른 글
| [운영체제 - 질문정리 III] 유저모드 커널모드, 스케줄링, 인터럽트, IPC (0) | 2022.06.28 |
|---|---|
| [운영체제 - 질문정리 II] 뮤텍스&세마포어, 데드락 (0) | 2022.06.28 |
| [네트워크 질문] OSI 7계층 (추가내용) (0) | 2022.04.13 |

댓글